The Hidden Mystery behind WEB CRAWLING
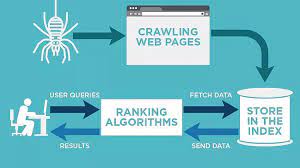
Web crawling is a process of extracting data from websites and storing it in a format that can be easily accessed and analyzed. It involves traversing through the website’s structure, following links from one page to another, and extracting data from the pages along the way.
Crawling can be used to collect a variety of information from websites, such as contact information, product details, pricing information, or even just plain old text. The data that is collected can then be used for a variety of purposes, such as lead generation, market research, or price comparisons.
There are a number of different approaches that can be used for web crawling, but the most common is to use software that simulates the actions of a human user. This approach is often referred to as “simulated browsing” or “spidering.”
The advantage of using a simulated browser is that it can automatically follow links from one page to another and extract data along the way. This eliminates the need for a human user to manually navigate through the website and also makes it possible to crawl websites that are not designed for human users (such as search engines).
There are a number of different software packages that can be used for web crawling, but the most popular is probably Scrapy. Scrapy is an open-source web crawling framework written in Python. It has a wide range of features, including the ability to follow links, extract data, and store the data in a variety of formats. Check RemoteDBA.
If you are looking for a tool to help you crawl websites and extract data, then Scrapy is definitely worth considering. In this article, we will take a closer look at what web crawling is, how it works, and some of the benefits of using Scrapy.
What is Web Crawling?
Web crawling is the process of automatically extracting data from websites. It involves traversing through the website’s structure, following links from one page to another, and extracting data from the pages along the way.
The data that is collected can be used for a variety of purposes, such as lead generation, market research, or price comparisons. There are a number of different approaches that can be used for web crawling, but the most common is to use software that simulates the actions of a human user.
This approach is often referred to as “simulated browsing” or “spidering.” The advantage of using a simulated browser is that it can automatically follow links from one page to another and extract data along the way. This eliminates the need for a human user to manually navigate through the website.
There are a number of different software packages that can be used for web crawling, but the most popular is probably Scrapy. Scrapy is an open-source web crawling framework written in Python. It has a wide range of features, including the ability to follow links, extract data, and store the data in a variety of formats.
If you are looking for a tool to help you crawl websites and extract data, then Scrapy is definitely worth considering.
How Does Web Crawling Work?
Web crawling is the process of automatically extracting data from websites. It involves traversing through the website’s structure, following links from one page to another, and extracting data from the pages along the way.
The data that is collected can be used for a variety of purposes, such as lead generation, market research, or price comparisons. There are a number of different approaches that can be used for web crawling, but the most common is to use software that simulates the actions of a human user.
This approach is often referred to as “simulated browsing” or “spidering.” The advantage of using a simulated browser is that it can automatically follow links from one page to another and extract data along the way. This eliminates the need for a human user to manually navigate through the website.
There are a number of different software packages that can be used for web crawling, but the most popular is probably Scrapy. Scrapy is an open-source web crawling framework written in Python. It has a wide range of features, including the ability to follow links, extract data, and store the data in a variety of formats.
Conclusion:
Web crawling is a process of automatically extracting data from websites. It can be used for a variety of purposes, such as lead generation, market research, or price comparisons. The most common way to do web crawling is to use software that simulates the actions of a human user.